
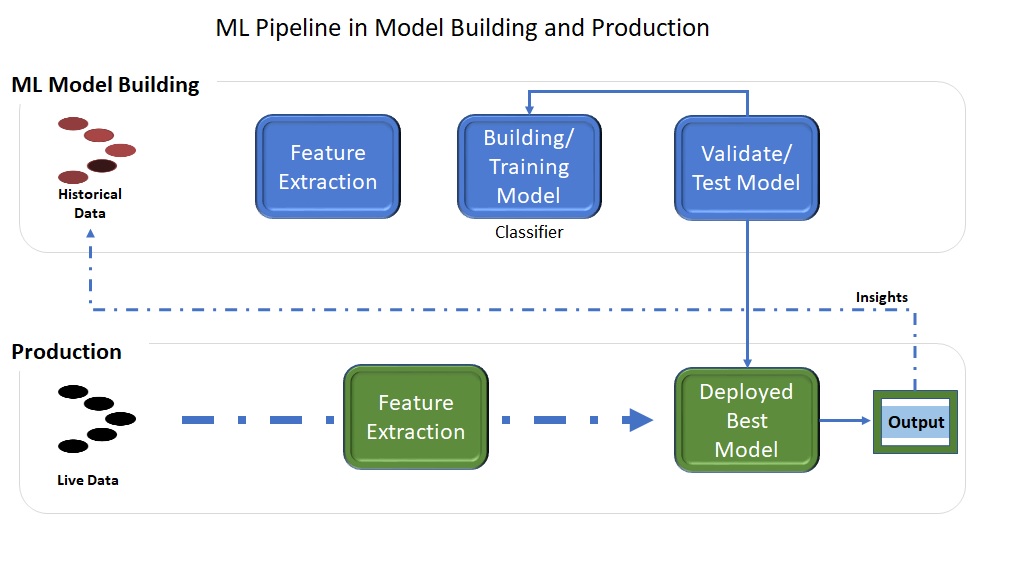
Machine Learning Pipeline

A machine learning pipeline is used to help automate machine learning workflows. They operate by enabling a sequence of data to be transformed and correlated together in a model that can be tested and evaluated to achieve an outcome, whether positive or negative.
The major blocks in this pipeline are Data Collection, Data processing, Feature Extraction and Model Engineering; this post explains these blocks at high level.
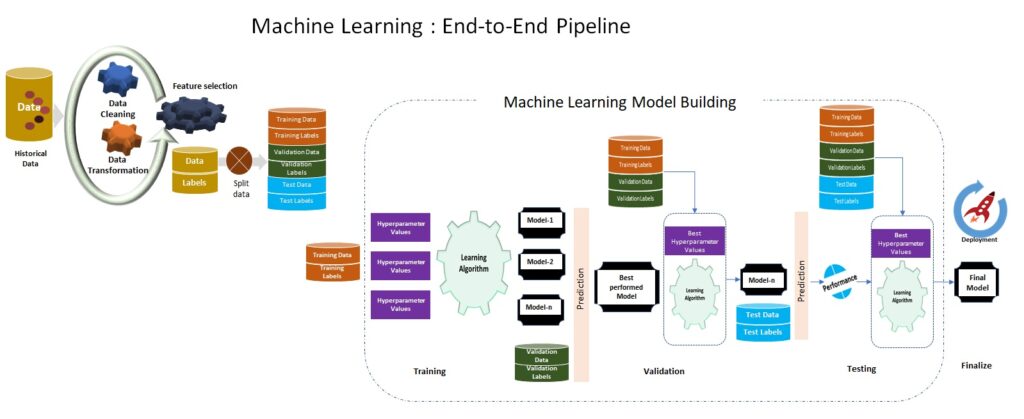
Data Collection:
In today’s world data is the fuel that powers many of the critical engines, from business intelligence to predictive analytics; data science to machine learning. As per the defined-problem, one has to find datasets that can be used to train machine learning models, which is done in three ways data discovery or data augmentation or data generation.
- Discovery: Data can be explored using explore systems(https://toolbox.google.com/datasetsearch…etc.) for searching datasets where the number of datasets tends to be high. OR can utilize shared system ( datahub, Kaggle…Etc..) readily available for sharing, even host models trained on the specific datasets.
- Generation: When none of the existing datasets suits our defined-problem that can be used for training, then another option is to generate the datasets either manually or automatically(using scripts). Here crowdsourcing platforms can be helpful for gathering and building specific dataset.
- Augmentation /Integration: When base data is short, the data augmentation adds value to base data by creating new data with different orientations( eg.: flip, rotation, crop, scale, add noise, translation …etc.)
Data Processing and Feature Engineering:
Machine learning uses algorithms to find patterns in data, and then uses a model that recognizes those patterns to make predictions on new data. The job of data processing and feature Engineering is to enhance the data in such a way that it increases the likelihood that the classification algorithm will be able to make meaningful predictions.
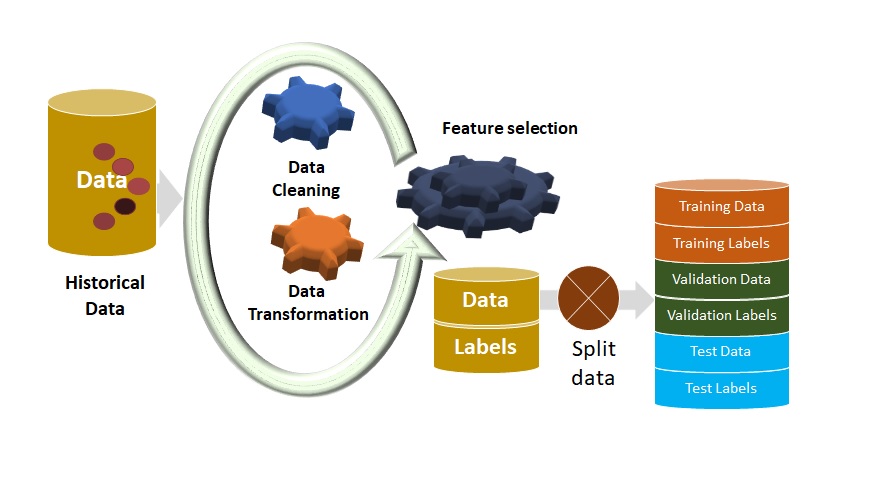
Data Cleaning:
The data cleaning is process of fixing or removing the anomalies discovered. Here are few general techniques
- Fill-out missing values / Removing rows with missing values
- Fix Syntax errors
- Handle Type conversion
- Resolve Duplicates
- Remove Irrelevant data
- …
Data Transformation:
Good Machine learning models are built based on good data that is used to train models. Data transformation predominantly deals with normalizing also known as scaling data, handling skewness and aggregation of attributes.
- Normalization – here numerical data is converted into the specified range, i.e., between 0 and one so that scaling of data can be performed.
- Aggregation – The concept can be derived from the word itself, this method is used to combine the features into one. For example, combining two categories can be used to form a new group.
- Generalization – here lower level attributes are converted to a higher standard.
Feature Selection:
Feature Selection is important in machine learning, to avoid “garbage in-garbage out”, we try to identify relevant attributes of the data which can be useful for the analysis and removing those attributes which are not so relevant for the analysis. Need to be very careful about the data that is being fed to the model, so we automatically or manually select those features which contribute most to our prediction.
Apart from identify relevant attributes, feature selection helps to :
- enable the machine learning algorithm to train faster.
- reduces overfitting.
- eliminate the effects of the curse of dimensionality
- improve the accuracy of a model if the right subset is chosen.
- reduce the complexity of a model and makes it easier to interpret.
The Feature selection techniques generally used today are – Filter methods, Wrapper methods, and Embedded methods.
Splitting the Data:
After raw data goes through Data cleaning, Data transformation and selected key attributes, we split data into training data and test data. The training set contains a known output and the model learns on this data in order to be generalized to other data later on. We have the test dataset in order to test our model’s prediction on this subset. A better way of splitting the data is to not split it only into training and testing sets, but to also include a validation set.
- Training set (60% of the original data set): This is used to build up our prediction algorithm, Each algorithm has its own parameter options (layers in a Neural Network, the number of trees in a Random Forest, etc.). For each of algorithms, we will pick one option, that’s why we have a training set. we create multiple algorithms in order to compare their performances during the Cross-Validation Phase.
- Cross-Validation set (20% of the original data set): This data set is used to compare the performances of the prediction algorithms that were created based on the training set. We choose the algorithm that has the best performance.
- Test set (20% of the original data set): Now we have chosen our preferred prediction algorithm but we don’t know yet how it’s going to perform on completely unseen real-world data. So, we apply our chosen prediction algorithm on our test set in order to see how it’s going to perform so we can have an idea about our algorithm’s performance on unseen data.
Model Engineering:
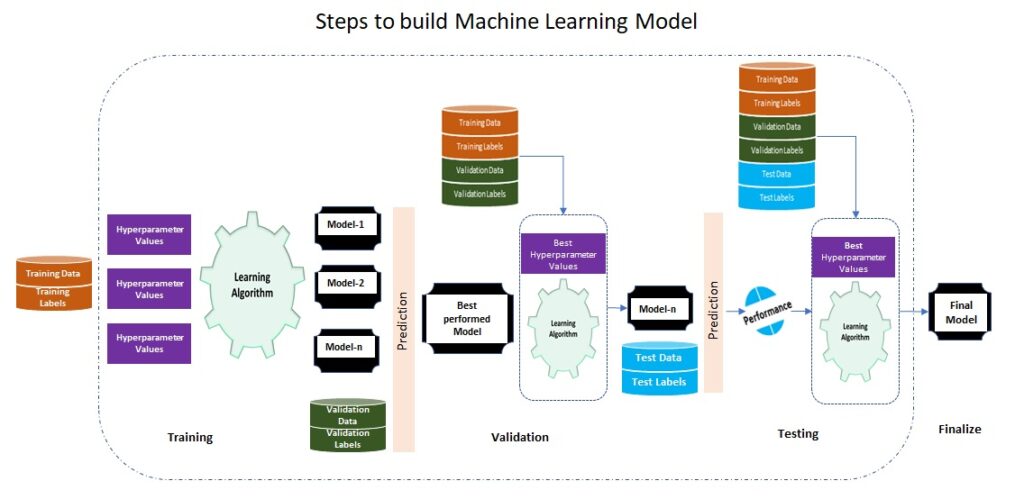
Training a model is considered as most complex step in the pipeline, but algorithms today are tested, straightforward and agnostic to the problem we plan to solve, once the data pre-processing is over, the real action starts! We feed data into an machine learning algorithm, it learns the relationship between features and goal. This relationship is our Machine Learning model. When enough right features are provided, our algorithm will learn a model which reliably turns data into predictions.
Today there are hundreds of distinct Machine Learning algorithms (neural networks, logistic regression, decision trees, etc.), each algorithm learns in different ways, and it’s difficult to know which will perform best on our data-set, so selection happens after multiple experiment trials by changing algorithms and fine-tuning them using Hyper-parameters, the winner-algorithm based model will be our model for test & validation.
Final Thoughts
Pipelines are a simple and effective way to manage complex machine learning workflows and nowadays pipeline usage become more common as we see AI systems broadly deployed into production, It’s power stands out even more when we get to cross-validation for hyper-parameter tuning. Overall, using the Pipeline will be a major step in making machine learning scalable, easy, and enjoyable.
